
Summary
Wondering how data annotation is evolving in 2024? This blog covers key trends like synthetic data, multimodal labeling, and real-time annotations that are redefining the AI space. Stay up-to-date with these trends to drive innovation and develop more innovative AI applications.
—------------------------------------------------------------------------------------------------------------------
One thing that made headlines every now and then throughout 2024 is the “rising adoption of artificial intelligence across industries.” From chatbots to advanced diagnostics solutions, AI has infiltrated every facet of our lives. And with this rising adoption, the demand for the fuel supporting it, i.e., high-quality and accurate training data, has also increased. As per the latest report, the global data annotation market is forecasted to reach $6.45 billion by 2027. But that’s not all. As the AI models are evolving, handling more complex language processing and computer vision tasks, they require more nuanced, diverse, and contextually rich data to perform at their best. This is changing the current state of data annotation, giving rise to new trends. Let’s explore these trends so you can stay up-to-date to drive innovation.
Top Data Annotation Trends in 2024 Redefining the AI Space
Use of Synthetic Data for AI Model Training
To deal with the training data availability crisis and the high cost of human-generated data, companies are now shifting to synthetic data. As the name indicates, it is an artificially generated dataset mimicking real-world scenarios. Tech giants are betting on this approach, with brands like NVIDIA launching their open models (named Nemotron-4 340B) to generate synthetic data. While the current market size of synthetic data is worth $0.4 billion, it is forecasted to grow at a 42.14% CAGR to value $19.22 billion in 2035.
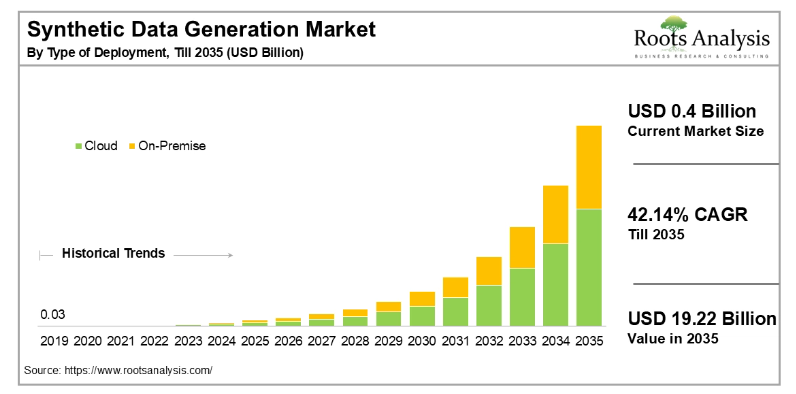
While the use of synthetic data for the AI model seems to be futuristic, its success depends on one factor - the quality of the generated data. Poorly designed synthetic datasets could introduce bias or inaccuracies, impairing model performance and negating the advantages they promise.
Another concern associated with using synthetic data is the likelihood of generalization. When AI models are repeatedly trained on artificially generated data, their outputs start showing hallucinations, questioning the long-term viability of the system. Hence, it is crucial to maintain an appropriate balance between the real-world and synthetic data for efficient AI model training.
Multimodal Data Annotation is on the Rise
There has been a rising demand for advanced AI systems that interact with the real world dynamically, such as robots, virtual assistants, and autonomous vehicles. These systems require diverse data formats to perform complicated tasks. For example, a virtual assistant may need to analyze text commands, understand spoken language, and interpret gestures simultaneously to help users with their queries.
To ensure these systems can “see,” “hear,” and “understand” seamlessly, companies are increasingly investing in multimodal data annotation. This process requires advanced labeling techniques, where each data type (e.g., a video frame and its corresponding audio) is annotated accurately and synchronized to train AI models holistically.
While multimodal annotation helps make AI systems more responsive and context-aware, it also has some challenges. For example, ensuring synchronization across different modalities, managing large datasets, and avoiding bias in multimodal systems require highly skilled annotation teams and advanced tools. To streamline these processes, companies are now turning to specialized third-party providers and AI-assisted annotation platforms, ensuring high-quality datasets while keeping costs in check.
Rising Demand for Industry-Specific Automation Solutions
Instead of a one-size-fits-all application, businesses are now shifting to industry-specific solutions for their unique operational needs. To create these industry-specific automation solutions, domain-specific training datasets are required.
For instance, the development of AI-assisted medical tools demands datasets with accurate labeling of CT scans, MRIs, X-rays, and other diagnostic reports. Similarly, visual data such as LiDAR scans and aerial footage of traffic must be labeled accurately to develop ADAS (advanced driver-assisted systems) applications for autonomous vehicles. To fulfill these demands, companies are now relying on niche-based data labeling services or building in-house expertise to ensure training datasets meet the rigorous demands of their sectors.
Integration of Automated Data Annotation Tools
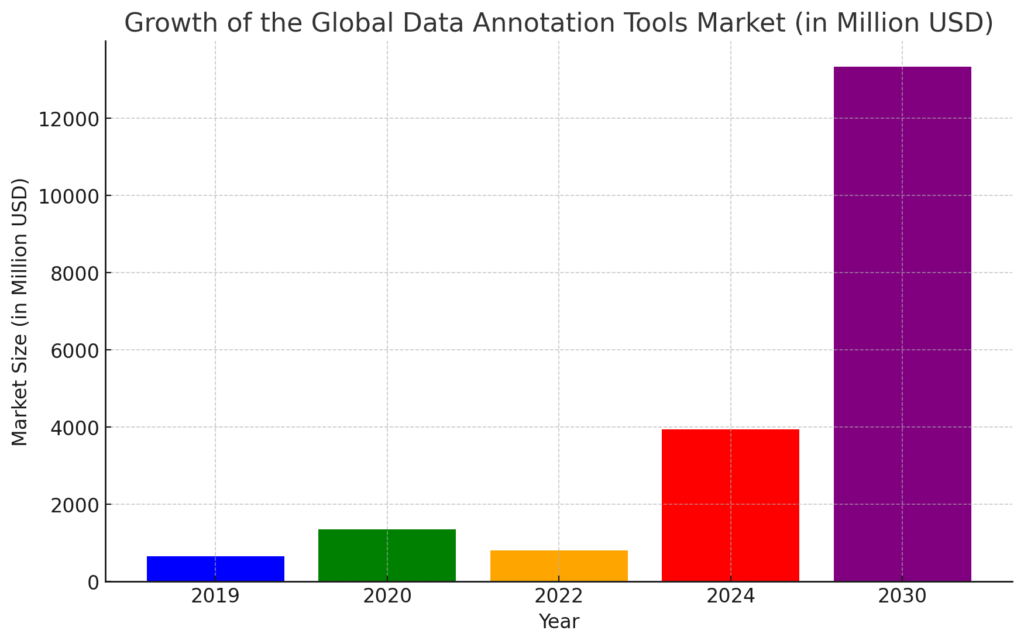
As the need for niche-specific AI applications grows, so does the reliance on custom data annotation tools to accelerate the process. In 2024, the global data annotation tool market is valued at $2.2 billion and is projected to grow at a CAGR of 27.4% through 2031. The key driver behind this growth is the emergence of edge AI applications.
As more organizations move towards deploying AI models directly on edge devices like IoT sensors, there is a need for real-time annotated data, driving demand for specialized annotation platforms that can handle such dynamic datasets. These tools (such as Scale.AI, Appen, LabelBox, and Labellerr's Image Annotation Platform) not only help annotate complex datasets—like medical imaging, drone surveillance footage, or financial transactions—but also enhance process efficiency by integrating automation with human oversight.
Real-Time Data Annotation for Adaptive AI Models
AI isn’t a set-it-and-forget-it solution. As the world around us changes, AI models need real-time, accurate, and up-to-date training data to stay relevant and responsive in dynamic environments.
Real-time data annotation ensures that the information feeding these models reflects the latest patterns and trends, making them more accurate and reliable. It’s like giving the AI a real-time sense of what’s happening right now so they can continuously learn, evolve, and respond.
Increased Adoption of Human-in-the-Loop (HITL) Systems
As concerns related to AI models’ explainability, reliability, and transparency are growing, businesses are increasingly adopting the human-in-the-loop approach to support the active learning and rapid adaptation of AI solutions to real-world scenarios [Source]. Also known as hybrid intelligence, this approach allows organizations to integrate subject matter experts in the data annotation process for fine-tuning AI models with real-time feedback and adjustments.
Subject matter experts feed AI models with real-world, context-rich, accurate training data that automated data annotation tools might overlook to mitigate bias and false predictions. This approach is particularly effective in adaptive learning scenarios where continuous data refinement is essential, such as predictive maintenance, sentiment analysis, medical diagnostics, and wearable robotics.
Practical ways to implement a human-in-the-loop approach for data annotation quality assurance:
To incorporate human supervision into their data labeling process, organizations are adopting one of these strategies:
- Hiring in-house data annotation experts to build a dedicated team that works on large-scale projects and meets the company’s quality expectations and labeling criteria.
- outsourced sales and data annotation services to a reliable third-party provider to ensure scalability and cost-effectiveness. This approach is particularly beneficial when businesses want to avoid heavy investments in infrastructure and employee training. A dedicated team of experienced professionals manages custom data annotation needs with precision, leveraging leading labeling tools while adhering to compliance and delivery timelines.
Growing Focus on Privacy-Preserving Annotation
While businesses are adopting automated tools to meet the rising demands of high-quality training datasets, they also have concerns about data privacy in annotation. A vast amount of sensitive information gets exposed to third-party tools for automated data labeling. If even a single data breach occurs, that information could be exposed to the wrong people and potentially have catastrophic consequences. To avoid this, the focus is now shifting to privacy-preserving annotation. This approach involves:
- Federated Learning: Data remains on local devices, and only model updates (not raw data) are shared to train AI collectively without centralizing sensitive information.
- Secure Multi-Party Computation (SMPC): Multiple parties can collaboratively annotate data without revealing their individual inputs, ensuring privacy throughout the process.
- Homomorphic Encryption: Encrypted data is labeled directly, with no need to decrypt, maintaining data privacy during annotation.
- Zero-Knowledge Proofs (ZKPs): Verifiers can confirm data annotations without accessing the underlying sensitive data, ensuring secure verification.
What is Next?
As technology advances rapidly, we expect that by 2025, data annotation trends will move beyond real-time updates and privacy-preserving methods to self-supervised learning and autonomous annotation systems. However, that will not eliminate the need for a human-in-the-loop approach. As AI takes on more complex tasks, humans will still be essential to managing edge cases, correcting biases, and providing a context where technology falls short. We can also expect some breakthroughs in explainable AI (XAI) where annotation systems would not only require labeling datasets but also provide insights into model decisions, making AI more transparent and trustworthy.
In essence, 2025 will push the boundaries of automation, multi-functional AI capabilities, and transparency in ways that redefine how we understand and manage annotated data. To stay ahead, now is the time to implement 2024’s data annotation trends—whether through outsourcing or building in-house capabilities.



